 rafacbta 99
rafacbta 99
Unidad 1. Fundamentos de bases de datos distribuidas
1.1. Conceptos básicos de bases de datos distribuidas.
1.2. Objetivos de las bases de datos distribuidas.
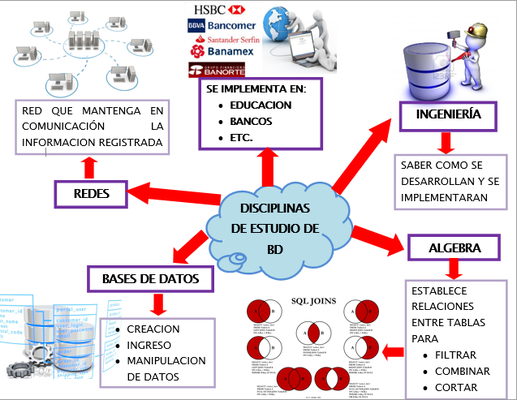
1.3. Disciplinas de estudio de bases de datos distribuidas.
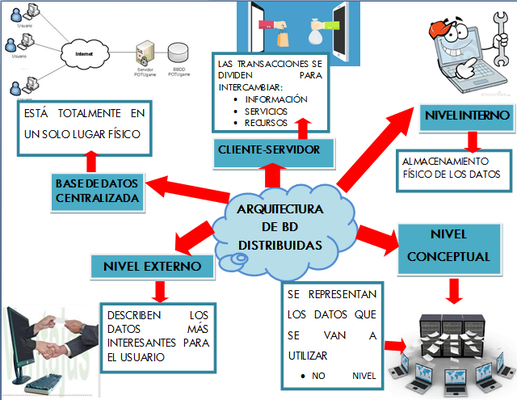
1.4. Arquitectura de bases de datos distribuidas.
Unidad 2. Diseño de bases de datos distribuidas
Subpáginas (5): 2.1. Consideraciones de diseño de bases de datos distribuidas 2.2. Niveles de transparencia 2.3. Fragmentación de datos 2.4. Distribución de datos 2.5. Diccionario de datos
Unidad 3. Procesamiento de consultas distribuidas
Unidad 4. Manejo de Transacciones
TEMA 1: INTRODUCCIÓN
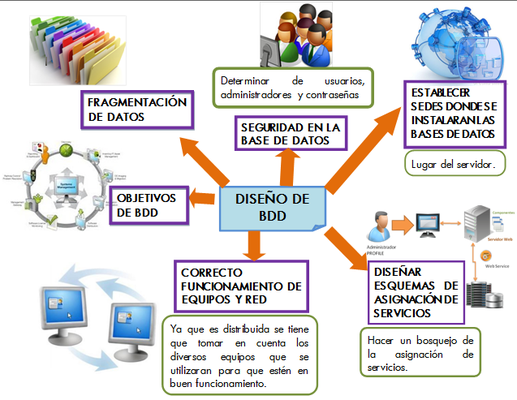
Es importante antes de crear una base de datos distribuida planear su distribución por medio de un diseño, este nos facilitara el acceso a la información y tener buenas transacciones al momento de las consultas.
CONTENIDO
1) Establecer sedes donde se instalaran las bases de datos
2) Diseñar esquemas de asignación de servicios
3) Correcto funcionamiento de equipos y red
4) Elaborar Bosquejos de transacciones
5) Determinar usuarios y administradores
CONCLUSIÓN
Ahora que se ah identificado cuales consideraciones hay que tomar al momento de crear la base de datos, se puede realizar un bosquejo de cómo se llevara a cabo las relaciones y que no tenga conflicto al momento de realizar las transacciones.
TEMA DOS INTRODUCCIÓN
En esta investigación se pretende identificar cuáles son los niveles de transparencia en una base de datos distribuida, con ello se podrá valorar su importancia y lo importante que son al momento de crear una BDD.
Con la elaboración del presente documento se integrarán distintos puntos sumamente importantes relacionados directamente con lo hemos tratado en clase y con ello evolucionando a través de los años y desarrollándose en cualquier aspecto.
CONTENIDO
El propósito de establecer una arquitectura de un sistema de bases de datos distribuidas es ofrecer un nivel de transparencia adecuado para el manejo de la información.
La responsabilidad sobre el manejo de transparencia debe estar compartida tanto por el sistema operativo, el sistema de manejo de bases de datos y el lenguaje de acceso a la base de datos distribuida.
El sistema de bases de datos distribuido permite proporcionar independencia de los datos. La independencia de datos se puede dar en dos aspectos: lógica y física.
1 Independencia lógica de datos: Se refiere a la inmunidad de las aplicaciones de usuario a los cambios en la estructura lógica de la base de datos. Esto permite que un cambio en la definición de un esquema no debe afectar a las aplicaciones de usuario. Por ejemplo, el agregar un nuevo atributo a una relación, la creación de una nueva relación, el reordenamiento lógico de algunos atributos.
2 Independencia física de datos: Se refiere al ocultamiento de los detalles sobre las estructuras de almacenamiento a las aplicaciones de usuario. la descripción física de datos puede cambiar sin afectar a las aplicaciones de usuario. Por ejemplo, los datos pueden ser movidos de un disco a otro, o la organización de los datos puede cambiar.
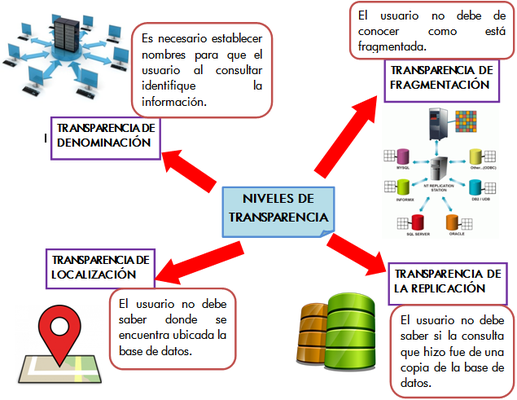
Transparencia de fragmentación: El usuario no sabe cómo están fragmentadas las tabla en las base de datos. El usuario no necesita especificar el nombre de los fragmentos de las tablas.
Transparencia de la ubicación: Puede darse el caso de que el usuario conozca cómo se encuentran fragmentadas las tablas, pero no conoce y no es necesario que sepa la ubicación de estas.
Transparencia de la replicación: El usuario no sabe qué nodos que contienen los fragmentos son replicados, tampoco es necesario que lo sepa para poner en funcionamiento una aplicación.
Transparencia de denominación: Cada elemento de la base de datos distribuida debe tener un nombre igual en cada uno de los nodos en que se encuentra distribuida, eso hace que el usuario manipule los elementos como si estudiaran centralizados en una sola base de datos.
Transparencia de concurrencia: Los sistemas de gestión de base de datos distribuidas brindan transparencia de concurrencia si es que las transacciones independientes son lógicas y tienen similitud con que se puedan hacer al mismo tiempo, es decir los resultados serían los mismos se hiciere de una sola vez. Esto sucede con la replicación, por ejemplo, dado que este proceso es asíncrono.
Continuación
Transparencia de transacción: Se garantiza que todas las transacciones mantengan la integridad y coherencia de datos de la base de datos distribuida, es decir en todos sus nodos y fragmentos. Por ejemplo se puede utilizar todos los fragmentos de una tabla – estos fragmentos pueden estar físicamente en diferentes ubicaciones – de una sola vez. Una transacción internamente está dividida en sub transacciones para ocupar cada uno de los nodos que contenga los datos que se requiere, esto no es visible para el usuario. Este, simplemente envía una sola transacción.
Transparencia respecto a fallos: Garantizar la atomicidad de la transacción, es decir mostrar los resultados si es que todas las sub transacciones no tuvieron error, o parar todo el proceso y algún subproceso tuvo error. Por lo tanto SGBDD debe sincronizar todas las sub transacciones mediante la transacción global.
CONCLUSIÓN
Ahora que se conoce cuales son los niveles de transparencia, que aportan y para qué sirven, es muy importante implementarlos al momento de crear nuestra base de datos distribuida.
ahora para finalizar a lo largo de la investigación se verificaron distintos términos, los cuales fueron desenvolviéndose de manera rápida clara y concisa con ello proporcionando aprendizaje y
desarrollo de habilidades
TEMA 3: INTRODUCCIÓN
Durante la realización de esta investigación se relacionan distintos puntos sumamente importantes relacionados directamente con la tecnología de comunicación la cual a lo largo de los años ha ido incrementándose y desarrollándose en cualquier aspecto en esta investigación más dirigida hacia lo que sería base de datos.
CONTENIDO
1- Localización de procesamiento.
El distribuir los datos para maximizar el procesamiento local de cada localidad, corresponde al sencillo principio de colocar los datos donde corresponde.
2- Disponibilidad y confiabilidad en la distribución.
El sistema debe ser capaz de cambiar a otra alternativa cuando la información que debe ser acceda en condiciones normales no se encuentra disponible.
3- Distribución de la carga de trabajo.
La distribución de la carga de trabajo se realiza para aprovechar las ventajas de la computadora en cada localidad.
4- Costo de almacenamiento y disponibilidad de los datos.
La BD debe reflejar el coste y disponibilidad de almacenamiento en las diferentes localidades.
La principal ventaja de los sistemas distribuidos es la capacidad de compartir y acceder a la información de una forma fiable y eficaz.
-Utilización compartida de los datos y distribución del control
-Fiabilidad y disponibilidad
-Agilización del procesamiento de consultas
La desventaja principal de los sistemas distribuidos es la mayor complejidad que se requiere para garantizar una coordinación adecuada entre localidades.
El aumento de la complejidad se refleja en:
Coste del desarrollo de software: es más difícil estructura un sistema de bases de datos distribuidos y por tanto su coste es menor
Mayor posibilidad de errores: puesto que las localidades del sistema distribuido operan en paralelo, es más difícil garantizar que los algoritmos sean correctos.
Mayor tiempo extra de procesamiento: el intercambio de mensajes y los cálculos adicionales son una forma de tiempo extra que no existe en los sistemas centralizados.
CONCLUSIÓN
Ahora que se ha identificado y verificado cualquier tema relacionado con las anteriores consideraciones que hay que tomar al momento de la distribución de datos.